Note
Click here to download the full example code
Scaling up multi-head attention layers¶
Let’s compare the performances of PyTorch and KeOps for simple attention computations, with an increasing number of tokens, attention heads and embedding features.
Setup¶
import numpy as np
import torch
from matplotlib import pyplot as plt
from functools import partial
from benchmark_utils import flatten, random_normal, full_benchmark
from torch.nn import MultiheadAttention as MultiheadAttention_torch
from pykeops.torch import MultiheadAttention as MultiheadAttention_keops
use_cuda = torch.cuda.is_available()
Benchmark specifications:
# Sequence lengths that we'll loop upon:
problem_sizes = [2 ** k for k in range(8, 18)]
Synthetic data:
def generate_sequences(
target_source_len, embed_dim=1, device="cuda", lang="torch", batchsize=1, **kwargs
):
"""Generates query, key and value arrays.
Args:
target_source_len (int): length of the target and source sequences.
embed_dim (int): dimension of the feature vectors. Default to 1.
device (str, optional): "cuda", "cpu", etc. Defaults to "cuda".
lang (str, optional): "torch", "numpy", etc. Defaults to "torch".
batchsize (int, optional): number of experiments to run in parallel. Defaults to 1.
Returns:
3-uple of arrays: query, key, value
"""
randn = random_normal(device=device, lang=lang)
target_len = target_source_len
source_len = target_source_len
if callable(batchsize):
batchsize = batchsize(target_source_len)
query = randn((target_len, batchsize, embed_dim))
key = randn((source_len, batchsize, embed_dim))
value = randn((source_len, batchsize, embed_dim))
return query, key, value
Our main experiment: benchmark the forward and forward+backward passes through the multi-head attention layer using both PyTorch and KeOps backends.
def run_experiment(embed_dim=1, num_heads=1):
generate_samples = partial(generate_sequences, embed_dim=embed_dim)
# To best saturate our GPU, we use batch sizes that are (approximately)
# "as large as possible" without throwing a memory overflow.
# To take into account the wide variations of memory footprint between
# different implementations, we specify this parameter through
# "lists" of values for increasing sequence lengths:
batchmems_torch = {
2 ** 7: 2 ** 15,
2 ** 8: 2 ** 14,
2 ** 9: 2 ** 12,
2 ** 10: 2 ** 8,
}
batchmems_keops = {
2 ** 7: 2 ** 20,
2 ** 8: 2 ** 19,
2 ** 9: 2 ** 18,
2 ** 10: 2 ** 17,
2 ** 11: 2 ** 12,
2 ** 12: 2 ** 11,
2 ** 13: 2 ** 10,
2 ** 14: 2 ** 9,
2 ** 15: 2 ** 8,
2 ** 16: 2 ** 7,
}
batchmems_nystroem = {
2 ** 7: 2 ** 13,
2 ** 8: 2 ** 13,
2 ** 9: 2 ** 13,
2 ** 10: 2 ** 12,
2 ** 11: 2 ** 11,
2 ** 12: 2 ** 10,
2 ** 13: 2 ** 9,
2 ** 14: 2 ** 8,
2 ** 15: 2 ** 7,
}
def batchsize_fun(n, batchmems=batchmems_torch, multiplier=4, **kwargs):
batchmem = batchmems.get(n, 1)
if batchmem <= multiplier * embed_dim:
batchsize = 1
else:
batchsize = batchmem // (multiplier * embed_dim)
return batchsize
batchsize_torch = partial(batchsize_fun, batchmems=batchmems_torch)
batchsize_keops = partial(batchsize_fun, batchmems=batchmems_keops)
batchsize_nystroem_64 = partial(batchsize_fun, batchmems=batchmems_nystroem)
batchsize_nystroem_256 = partial(
batchsize_fun, batchmems=batchmems_nystroem, multiplier=16
)
def attention(
query, key, value, use_keops=False, backward=True, landmarks=None, **kwargs
):
if landmarks is None and not use_keops:
layer = MultiheadAttention_torch(embed_dim, num_heads)
else:
layer = MultiheadAttention_keops(
embed_dim, num_heads, lazy=use_keops, landmarks=landmarks
)
if use_cuda:
layer = layer.cuda()
def to_call(query, key, value, **kwargs):
if backward:
query.requires_grad = True
key.requires_grad = True
value.requires_grad = True
out, _ = layer(query, key, value)
out.sum().backward()
return out
else:
return layer(query, key, value)
return to_call
routines = [
(
attention,
"PyTorch",
{
"batchsize": batchsize_torch,
"use_keops": False,
},
),
(
attention,
"PyTorch (Nyström landmarks = 256)",
{
"batchsize": batchsize_nystroem_256,
"use_keops": False,
"landmarks": 256,
},
),
(
attention,
"PyTorch (Nyström landmarks = 64)",
{
"batchsize": batchsize_nystroem_64,
"use_keops": False,
"landmarks": 64,
},
),
(
attention,
"KeOps",
{
"batchsize": batchsize_keops,
"use_keops": True,
},
),
(
attention,
"KeOps (Nyström landmarks = 256)",
{
"batchsize": batchsize_nystroem_256,
"use_keops": True,
"landmarks": 256,
},
),
(
attention,
"KeOps (Nyström landmarks = 64)",
{
"batchsize": batchsize_nystroem_64,
"use_keops": True,
"landmarks": 64,
},
),
]
full_benchmark(
f"Multi-head attention (forward+backward, embed_dim={embed_dim},n_heads={num_heads},heads_dim={embed_dim//num_heads})",
routines,
generate_samples,
problem_sizes=problem_sizes,
loops=[10, 1],
max_time=10,
red_time=1,
linestyles=[
"o-b",
"s--b",
"+:b",
"x-r",
"^--r",
"<:r",
],
xlabel="Sequence length",
)
Embeddings of dimension 64¶
Embedding of dimension 64 = 64 heads of dimension 1.
run_experiment(embed_dim=64, num_heads=64)
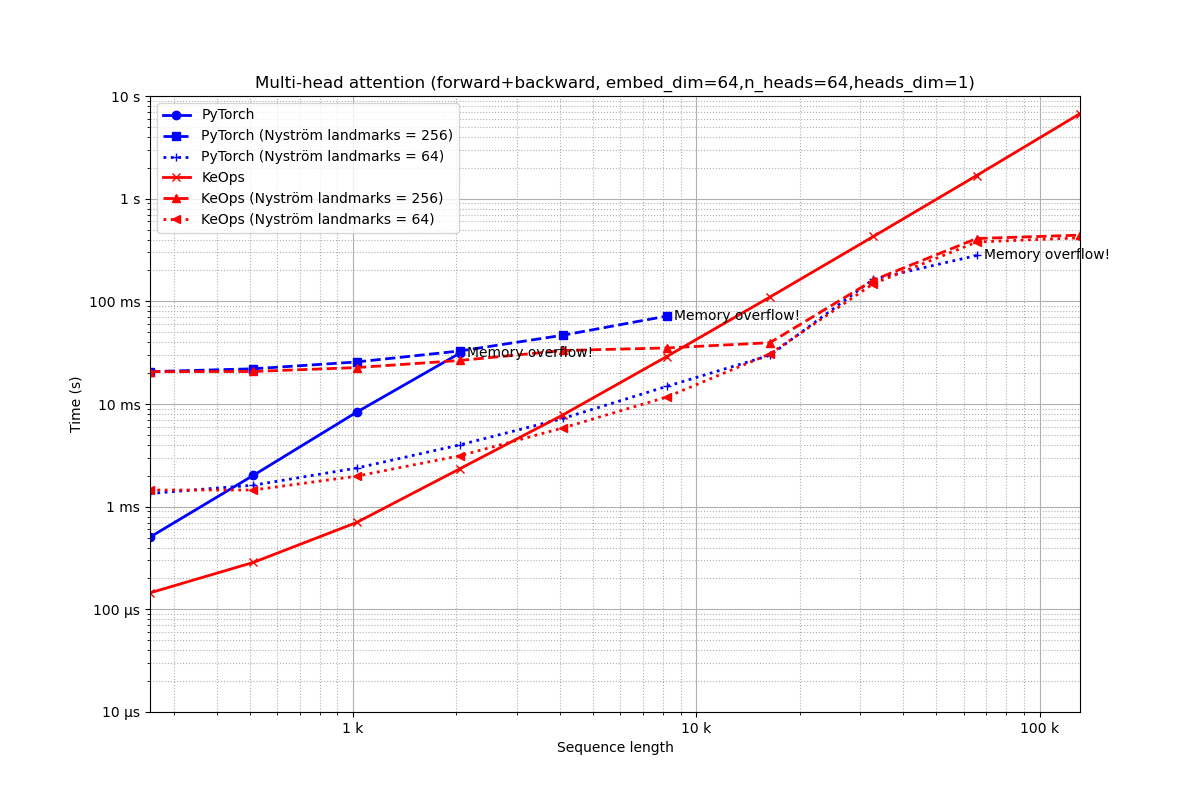
Out:
Benchmarking : Multi-head attention (forward+backward, embed_dim=64,n_heads=64,heads_dim=1) ===============================
PyTorch -------------
64x 10 loops of size 256 : 64x 10x 505.1 µs
16x 10 loops of size 512 : 16x 10x 2.0 ms
1x 10 loops of size 1 k: 1x 10x 8.3 ms
1x 10 loops of size 2 k: 1x 10x 31.3 ms
CUDA out of memory. Tried to allocate 4.00 GiB (GPU 0; 10.76 GiB total capacity; 8.07 GiB already allocated; 1.65 GiB free; 8.07 GiB reserved in total by PyTorch)
** Runtime error!
PyTorch (Nyström landmarks = 256) -------------
8x 10 loops of size 256 : 8x 10x 20.7 ms
8x 10 loops of size 512 : 8x 10x 22.0 ms
4x 10 loops of size 1 k: 4x 10x 25.7 ms
2x 10 loops of size 2 k: 2x 10x 32.9 ms
1x 10 loops of size 4 k: 1x 10x 46.8 ms
1x 10 loops of size 8 k: 1x 10x 71.8 ms
CUDA out of memory. Tried to allocate 1024.00 MiB (GPU 0; 10.76 GiB total capacity; 7.65 GiB already allocated; 678.56 MiB free; 9.06 GiB reserved in total by PyTorch)
** Runtime error!
PyTorch (Nyström landmarks = 64) -------------
32x 10 loops of size 256 : 32x 10x 1.3 ms
32x 10 loops of size 512 : 32x 10x 1.6 ms
16x 10 loops of size 1 k: 16x 10x 2.4 ms
8x 10 loops of size 2 k: 8x 10x 4.0 ms
4x 10 loops of size 4 k: 4x 10x 7.2 ms
2x 10 loops of size 8 k: 2x 10x 14.8 ms
1x 10 loops of size 16 k: 1x 10x 29.8 ms
1x 10 loops of size 33 k: 1x 10x 163.9 ms
1x 1 loops of size 66 k: 1x 1x 279.9 ms
CUDA out of memory. Tried to allocate 2.00 GiB (GPU 0; 10.76 GiB total capacity; 8.29 GiB already allocated; 640.56 MiB free; 9.10 GiB reserved in total by PyTorch)
** Runtime error!
KeOps -------------
2048x 10 loops of size 256 : 2048x 10x 144.7 µs
1024x 10 loops of size 512 : 1024x 10x 286.5 µs
512x 10 loops of size 1 k: 512x 10x 701.5 µs
16x 10 loops of size 2 k: 16x 10x 2.3 ms
8x 10 loops of size 4 k: 8x 10x 7.9 ms
4x 10 loops of size 8 k: 4x 10x 29.0 ms
2x 10 loops of size 16 k: 2x 10x 110.1 ms
1x 1 loops of size 33 k: 1x 1x 428.1 ms
1x 1 loops of size 66 k: 1x 1x 1.7 s
1x 1 loops of size 131 k: 1x 1x 6.7 s
KeOps (Nyström landmarks = 256) -------------
8x 10 loops of size 256 : 8x 10x 20.6 ms
8x 10 loops of size 512 : 8x 10x 20.7 ms
4x 10 loops of size 1 k: 4x 10x 22.6 ms
2x 10 loops of size 2 k: 2x 10x 26.6 ms
1x 10 loops of size 4 k: 1x 10x 33.2 ms
1x 10 loops of size 8 k: 1x 10x 35.1 ms
1x 10 loops of size 16 k: 1x 10x 39.6 ms
1x 10 loops of size 33 k: 1x 10x 160.8 ms
1x 1 loops of size 66 k: 1x 1x 409.3 ms
1x 1 loops of size 131 k: 1x 1x 441.4 ms
KeOps (Nyström landmarks = 64) -------------
32x 10 loops of size 256 : 32x 10x 1.5 ms
32x 10 loops of size 512 : 32x 10x 1.5 ms
16x 10 loops of size 1 k: 16x 10x 2.0 ms
8x 10 loops of size 2 k: 8x 10x 3.1 ms
4x 10 loops of size 4 k: 4x 10x 5.9 ms
2x 10 loops of size 8 k: 2x 10x 11.7 ms
1x 10 loops of size 16 k: 1x 10x 30.8 ms
1x 10 loops of size 33 k: 1x 10x 148.4 ms
1x 1 loops of size 66 k: 1x 1x 378.4 ms
1x 1 loops of size 131 k: 1x 1x 415.6 ms
Embedding of dimension 64 = 16 heads of dimension 4.
run_experiment(embed_dim=64, num_heads=16)
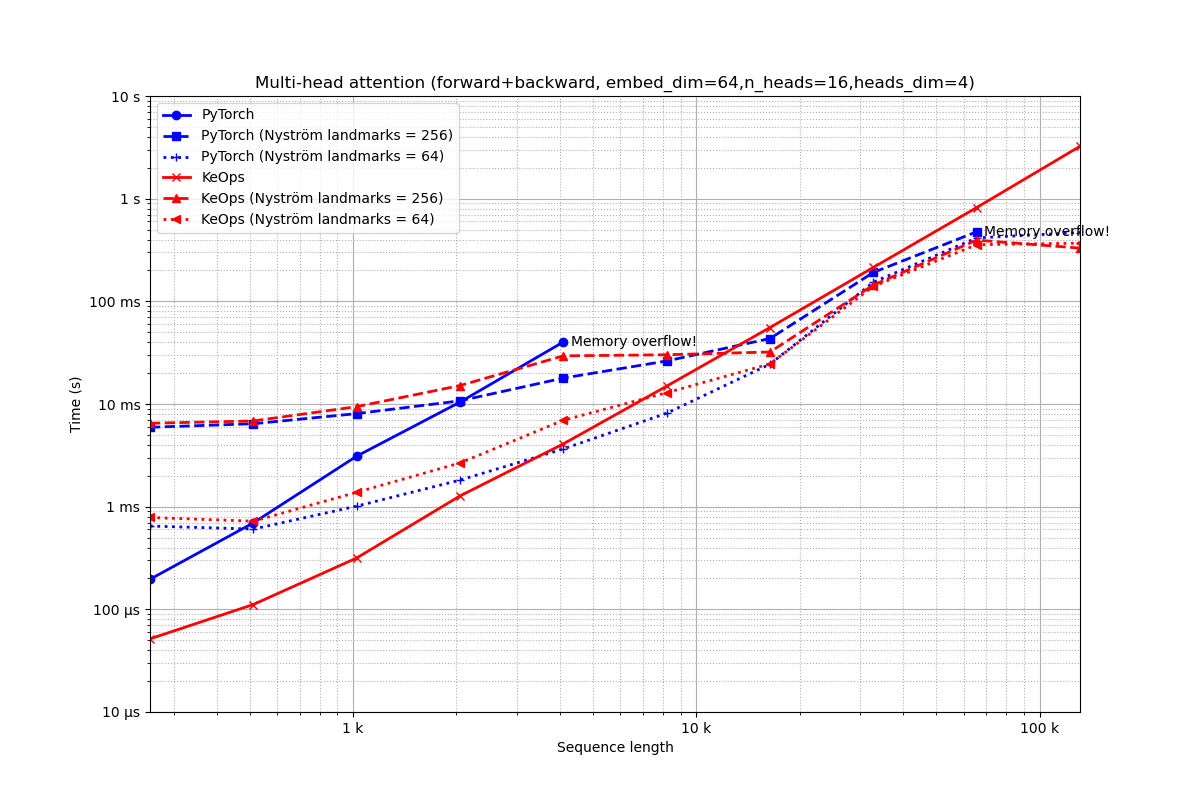
Out:
Benchmarking : Multi-head attention (forward+backward, embed_dim=64,n_heads=16,heads_dim=4) ===============================
PyTorch -------------
64x 10 loops of size 256 : 64x 10x 196.3 µs
16x 10 loops of size 512 : 16x 10x 695.3 µs
1x 10 loops of size 1 k: 1x 10x 3.1 ms
1x 10 loops of size 2 k: 1x 10x 10.4 ms
1x 10 loops of size 4 k: 1x 10x 40.2 ms
CUDA out of memory. Tried to allocate 4.00 GiB (GPU 0; 10.76 GiB total capacity; 8.27 GiB already allocated; 678.56 MiB free; 9.06 GiB reserved in total by PyTorch)
** Runtime error!
PyTorch (Nyström landmarks = 256) -------------
8x 10 loops of size 256 : 8x 10x 5.9 ms
8x 10 loops of size 512 : 8x 10x 6.4 ms
4x 10 loops of size 1 k: 4x 10x 8.1 ms
2x 10 loops of size 2 k: 2x 10x 10.7 ms
1x 10 loops of size 4 k: 1x 10x 17.9 ms
1x 10 loops of size 8 k: 1x 10x 26.2 ms
1x 10 loops of size 16 k: 1x 10x 43.4 ms
1x 10 loops of size 33 k: 1x 10x 191.1 ms
1x 1 loops of size 66 k: 1x 1x 476.0 ms
CUDA out of memory. Tried to allocate 2.00 GiB (GPU 0; 10.76 GiB total capacity; 8.40 GiB already allocated; 678.56 MiB free; 9.06 GiB reserved in total by PyTorch)
** Runtime error!
PyTorch (Nyström landmarks = 64) -------------
32x 10 loops of size 256 : 32x 10x 647.6 µs
32x 10 loops of size 512 : 32x 10x 605.0 µs
16x 10 loops of size 1 k: 16x 10x 1.0 ms
8x 10 loops of size 2 k: 8x 10x 1.8 ms
4x 10 loops of size 4 k: 4x 10x 3.7 ms
2x 10 loops of size 8 k: 2x 10x 8.1 ms
1x 10 loops of size 16 k: 1x 10x 24.4 ms
1x 10 loops of size 33 k: 1x 10x 153.5 ms
1x 1 loops of size 66 k: 1x 1x 414.7 ms
1x 1 loops of size 131 k: 1x 1x 468.1 ms
KeOps -------------
2048x 10 loops of size 256 : 2048x 10x 51.6 µs
1024x 10 loops of size 512 : 1024x 10x 111.4 µs
512x 10 loops of size 1 k: 512x 10x 316.3 µs
16x 10 loops of size 2 k: 16x 10x 1.3 ms
8x 10 loops of size 4 k: 8x 10x 4.1 ms
4x 10 loops of size 8 k: 4x 10x 14.9 ms
2x 10 loops of size 16 k: 2x 10x 55.6 ms
1x 10 loops of size 33 k: 1x 10x 213.8 ms
1x 1 loops of size 66 k: 1x 1x 819.3 ms
1x 1 loops of size 131 k: 1x 1x 3.2 s
KeOps (Nyström landmarks = 256) -------------
8x 10 loops of size 256 : 8x 10x 6.5 ms
8x 10 loops of size 512 : 8x 10x 6.8 ms
4x 10 loops of size 1 k: 4x 10x 9.4 ms
2x 10 loops of size 2 k: 2x 10x 15.1 ms
1x 10 loops of size 4 k: 1x 10x 29.4 ms
1x 10 loops of size 8 k: 1x 10x 30.2 ms
1x 10 loops of size 16 k: 1x 10x 32.1 ms
1x 10 loops of size 33 k: 1x 10x 144.1 ms
1x 1 loops of size 66 k: 1x 1x 394.6 ms
1x 1 loops of size 131 k: 1x 1x 329.8 ms
KeOps (Nyström landmarks = 64) -------------
32x 10 loops of size 256 : 32x 10x 784.6 µs
32x 10 loops of size 512 : 32x 10x 721.9 µs
16x 10 loops of size 1 k: 16x 10x 1.4 ms
8x 10 loops of size 2 k: 8x 10x 2.7 ms
4x 10 loops of size 4 k: 4x 10x 6.9 ms
2x 10 loops of size 8 k: 2x 10x 12.9 ms
1x 10 loops of size 16 k: 1x 10x 24.6 ms
1x 10 loops of size 33 k: 1x 10x 139.9 ms
1x 1 loops of size 66 k: 1x 1x 356.0 ms
1x 1 loops of size 131 k: 1x 1x 368.7 ms
Embedding of dimension 64 = 1 head of dimension 64.
run_experiment(embed_dim=64, num_heads=1)
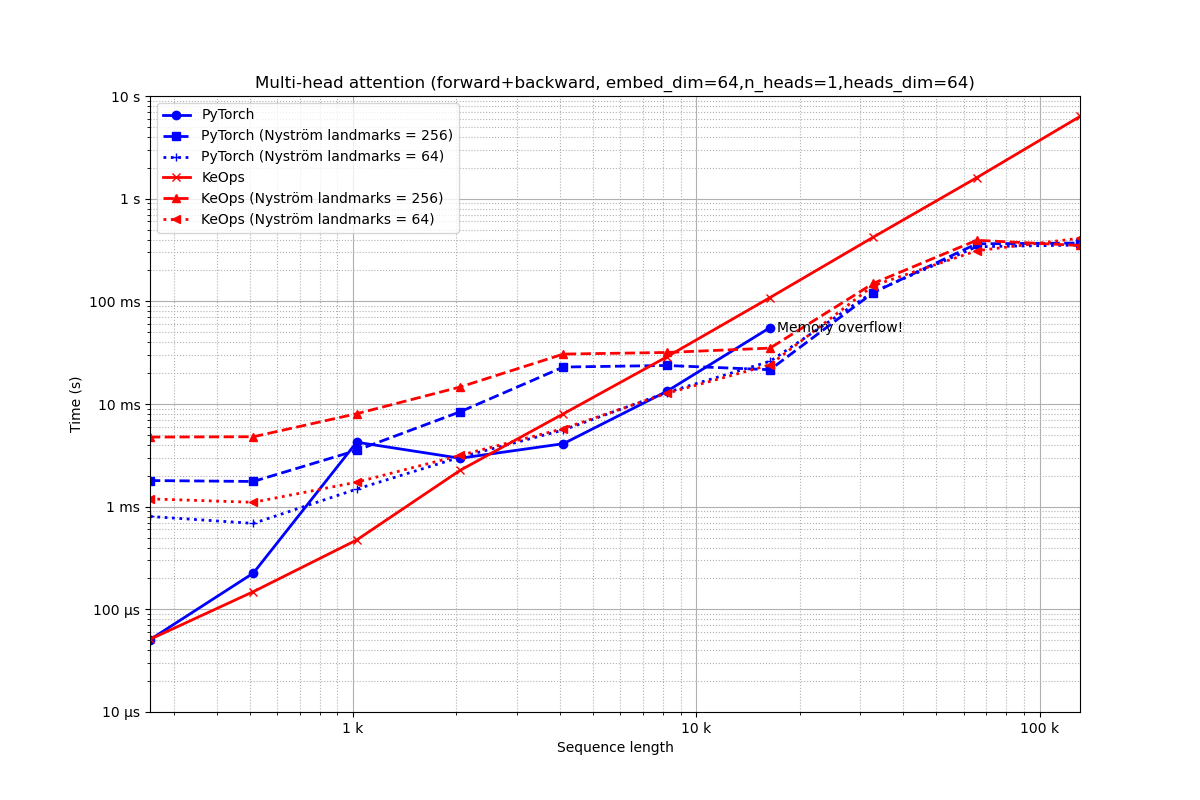
Out:
Benchmarking : Multi-head attention (forward+backward, embed_dim=64,n_heads=1,heads_dim=64) ===============================
PyTorch -------------
64x 10 loops of size 256 : 64x 10x 50.6 µs
16x 10 loops of size 512 : 16x 10x 225.3 µs
1x 10 loops of size 1 k: 1x 10x 4.2 ms
1x 10 loops of size 2 k: 1x 10x 3.0 ms
1x 10 loops of size 4 k: 1x 10x 4.1 ms
1x 10 loops of size 8 k: 1x 10x 13.3 ms
1x 10 loops of size 16 k: 1x 10x 55.5 ms
CUDA out of memory. Tried to allocate 4.00 GiB (GPU 0; 10.76 GiB total capacity; 8.06 GiB already allocated; 1.66 GiB free; 8.06 GiB reserved in total by PyTorch)
** Runtime error!
PyTorch (Nyström landmarks = 256) -------------
8x 10 loops of size 256 : 8x 10x 1.8 ms
8x 10 loops of size 512 : 8x 10x 1.8 ms
4x 10 loops of size 1 k: 4x 10x 3.5 ms
2x 10 loops of size 2 k: 2x 10x 8.4 ms
1x 10 loops of size 4 k: 1x 10x 22.9 ms
1x 10 loops of size 8 k: 1x 10x 23.7 ms
1x 10 loops of size 16 k: 1x 10x 21.6 ms
1x 10 loops of size 33 k: 1x 10x 121.7 ms
1x 1 loops of size 66 k: 1x 1x 363.4 ms
1x 1 loops of size 131 k: 1x 1x 369.8 ms
PyTorch (Nyström landmarks = 64) -------------
32x 10 loops of size 256 : 32x 10x 802.6 µs
32x 10 loops of size 512 : 32x 10x 687.2 µs
16x 10 loops of size 1 k: 16x 10x 1.5 ms
8x 10 loops of size 2 k: 8x 10x 3.0 ms
4x 10 loops of size 4 k: 4x 10x 5.6 ms
2x 10 loops of size 8 k: 2x 10x 12.9 ms
1x 10 loops of size 16 k: 1x 10x 26.1 ms
1x 10 loops of size 33 k: 1x 10x 123.8 ms
1x 1 loops of size 66 k: 1x 1x 340.3 ms
1x 1 loops of size 131 k: 1x 1x 353.6 ms
KeOps -------------
2048x 10 loops of size 256 : 2048x 10x 51.0 µs
1024x 10 loops of size 512 : 1024x 10x 148.6 µs
512x 10 loops of size 1 k: 512x 10x 473.4 µs
16x 10 loops of size 2 k: 16x 10x 2.3 ms
8x 10 loops of size 4 k: 8x 10x 8.0 ms
4x 10 loops of size 8 k: 4x 10x 28.7 ms
2x 10 loops of size 16 k: 2x 10x 108.8 ms
1x 1 loops of size 33 k: 1x 1x 422.2 ms
1x 1 loops of size 66 k: 1x 1x 1.6 s
1x 1 loops of size 131 k: 1x 1x 6.3 s
KeOps (Nyström landmarks = 256) -------------
8x 10 loops of size 256 : 8x 10x 4.8 ms
8x 10 loops of size 512 : 8x 10x 4.8 ms
4x 10 loops of size 1 k: 4x 10x 8.0 ms
2x 10 loops of size 2 k: 2x 10x 14.6 ms
1x 10 loops of size 4 k: 1x 10x 30.6 ms
1x 10 loops of size 8 k: 1x 10x 31.8 ms
1x 10 loops of size 16 k: 1x 10x 35.0 ms
1x 10 loops of size 33 k: 1x 10x 149.6 ms
1x 1 loops of size 66 k: 1x 1x 393.2 ms
1x 1 loops of size 131 k: 1x 1x 350.1 ms
KeOps (Nyström landmarks = 64) -------------
32x 10 loops of size 256 : 32x 10x 1.2 ms
32x 10 loops of size 512 : 32x 10x 1.1 ms
16x 10 loops of size 1 k: 16x 10x 1.7 ms
8x 10 loops of size 2 k: 8x 10x 3.2 ms
4x 10 loops of size 4 k: 4x 10x 5.8 ms
2x 10 loops of size 8 k: 2x 10x 12.7 ms
1x 10 loops of size 16 k: 1x 10x 24.1 ms
1x 10 loops of size 33 k: 1x 10x 142.3 ms
1x 1 loops of size 66 k: 1x 1x 310.9 ms
1x 1 loops of size 131 k: 1x 1x 412.0 ms
Embeddings of dimension 256¶
Embedding of dimension 256 = 64 heads of dimension 4.
run_experiment(embed_dim=256, num_heads=64)
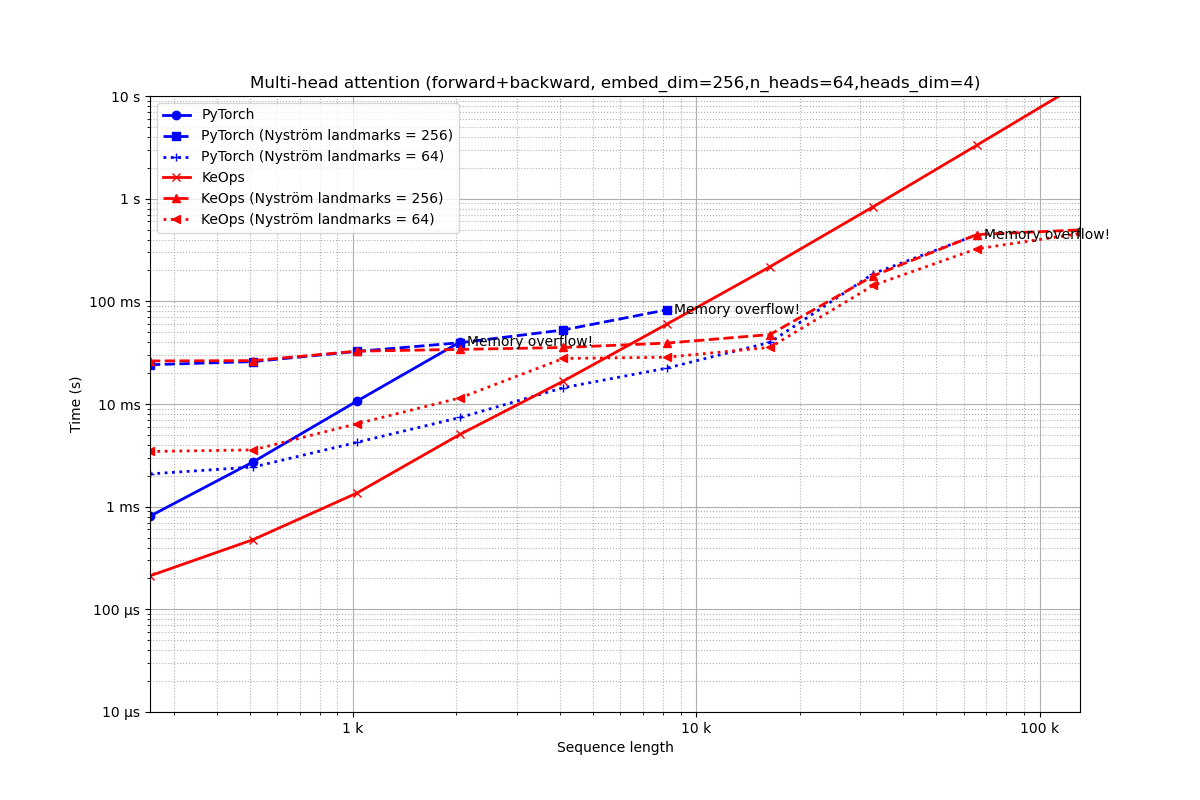
Out:
Benchmarking : Multi-head attention (forward+backward, embed_dim=256,n_heads=64,heads_dim=4) ===============================
PyTorch -------------
16x 10 loops of size 256 : 16x 10x 808.4 µs
4x 10 loops of size 512 : 4x 10x 2.7 ms
1x 10 loops of size 1 k: 1x 10x 10.6 ms
1x 10 loops of size 2 k: 1x 10x 40.1 ms
CUDA out of memory. Tried to allocate 4.00 GiB (GPU 0; 10.76 GiB total capacity; 8.10 GiB already allocated; 1.60 GiB free; 8.13 GiB reserved in total by PyTorch)
** Runtime error!
PyTorch (Nyström landmarks = 256) -------------
2x 10 loops of size 256 : 2x 10x 24.1 ms
2x 10 loops of size 512 : 2x 10x 25.9 ms
1x 10 loops of size 1 k: 1x 10x 32.5 ms
1x 10 loops of size 2 k: 1x 10x 39.5 ms
1x 10 loops of size 4 k: 1x 10x 52.6 ms
1x 10 loops of size 8 k: 1x 10x 82.6 ms
CUDA out of memory. Tried to allocate 1024.00 MiB (GPU 0; 10.76 GiB total capacity; 7.78 GiB already allocated; 612.56 MiB free; 9.13 GiB reserved in total by PyTorch)
** Runtime error!
PyTorch (Nyström landmarks = 64) -------------
8x 10 loops of size 256 : 8x 10x 2.1 ms
8x 10 loops of size 512 : 8x 10x 2.4 ms
4x 10 loops of size 1 k: 4x 10x 4.2 ms
2x 10 loops of size 2 k: 2x 10x 7.4 ms
1x 10 loops of size 4 k: 1x 10x 14.4 ms
1x 10 loops of size 8 k: 1x 10x 22.3 ms
1x 10 loops of size 16 k: 1x 10x 39.8 ms
1x 10 loops of size 33 k: 1x 10x 186.4 ms
1x 1 loops of size 66 k: 1x 1x 444.2 ms
CUDA out of memory. Tried to allocate 2.00 GiB (GPU 0; 10.76 GiB total capacity; 9.04 GiB already allocated; 702.56 MiB free; 9.04 GiB reserved in total by PyTorch)
** Runtime error!
KeOps -------------
512x 10 loops of size 256 : 512x 10x 211.9 µs
256x 10 loops of size 512 : 256x 10x 478.5 µs
128x 10 loops of size 1 k: 128x 10x 1.4 ms
4x 10 loops of size 2 k: 4x 10x 5.1 ms
2x 10 loops of size 4 k: 2x 10x 16.7 ms
1x 10 loops of size 8 k: 1x 10x 59.8 ms
1x 10 loops of size 16 k: 1x 10x 217.4 ms
1x 1 loops of size 33 k: 1x 1x 835.9 ms
1x 1 loops of size 66 k: 1x 1x 3.3 s
1x 1 loops of size 131 k: 1x 1x 13.2 s
** Too slow!
KeOps (Nyström landmarks = 256) -------------
2x 10 loops of size 256 : 2x 10x 26.3 ms
2x 10 loops of size 512 : 2x 10x 26.5 ms
1x 10 loops of size 1 k: 1x 10x 32.7 ms
1x 10 loops of size 2 k: 1x 10x 34.0 ms
1x 10 loops of size 4 k: 1x 10x 35.5 ms
1x 10 loops of size 8 k: 1x 10x 39.2 ms
1x 10 loops of size 16 k: 1x 10x 47.5 ms
1x 10 loops of size 33 k: 1x 10x 177.2 ms
1x 1 loops of size 66 k: 1x 1x 447.0 ms
1x 1 loops of size 131 k: 1x 1x 496.6 ms
KeOps (Nyström landmarks = 64) -------------
8x 10 loops of size 256 : 8x 10x 3.4 ms
8x 10 loops of size 512 : 8x 10x 3.6 ms
4x 10 loops of size 1 k: 4x 10x 6.4 ms
2x 10 loops of size 2 k: 2x 10x 11.5 ms
1x 10 loops of size 4 k: 1x 10x 27.8 ms
1x 10 loops of size 8 k: 1x 10x 28.5 ms
1x 10 loops of size 16 k: 1x 10x 35.6 ms
1x 10 loops of size 33 k: 1x 10x 143.2 ms
1x 1 loops of size 66 k: 1x 1x 324.5 ms
1x 1 loops of size 131 k: 1x 1x 457.2 ms
Embedding of dimension 256 = 16 heads of dimension 16.
run_experiment(embed_dim=256, num_heads=16)
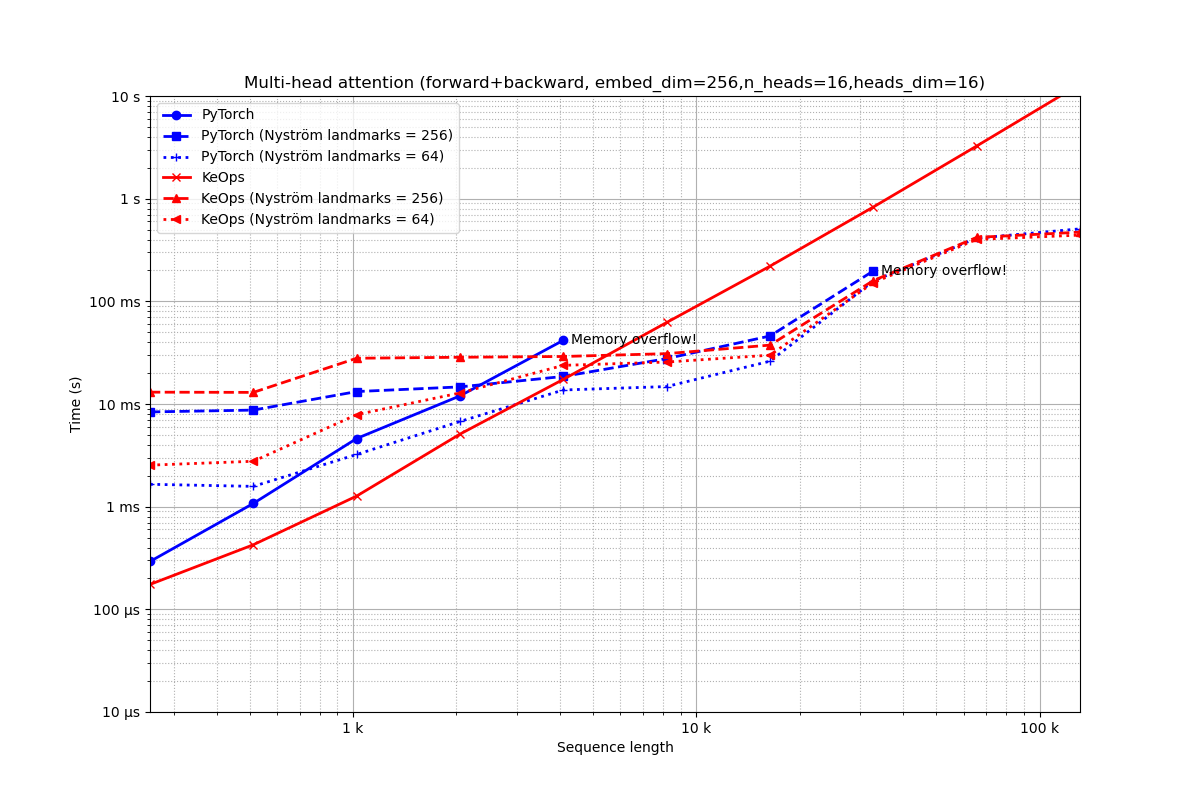
Out:
Benchmarking : Multi-head attention (forward+backward, embed_dim=256,n_heads=16,heads_dim=16) ===============================
PyTorch -------------
16x 10 loops of size 256 : 16x 10x 292.4 µs
4x 10 loops of size 512 : 4x 10x 1.1 ms
1x 10 loops of size 1 k: 1x 10x 4.6 ms
1x 10 loops of size 2 k: 1x 10x 12.0 ms
1x 10 loops of size 4 k: 1x 10x 41.7 ms
CUDA out of memory. Tried to allocate 4.00 GiB (GPU 0; 10.76 GiB total capacity; 8.32 GiB already allocated; 742.56 MiB free; 9.00 GiB reserved in total by PyTorch)
** Runtime error!
PyTorch (Nyström landmarks = 256) -------------
2x 10 loops of size 256 : 2x 10x 8.4 ms
2x 10 loops of size 512 : 2x 10x 8.7 ms
1x 10 loops of size 1 k: 1x 10x 13.2 ms
1x 10 loops of size 2 k: 1x 10x 14.7 ms
1x 10 loops of size 4 k: 1x 10x 18.5 ms
1x 10 loops of size 8 k: 1x 10x 27.7 ms
1x 10 loops of size 16 k: 1x 10x 46.0 ms
1x 10 loops of size 33 k: 1x 10x 197.6 ms
CUDA out of memory. Tried to allocate 1024.00 MiB (GPU 0; 10.76 GiB total capacity; 7.84 GiB already allocated; 740.56 MiB free; 9.00 GiB reserved in total by PyTorch)
** Runtime error!
PyTorch (Nyström landmarks = 64) -------------
8x 10 loops of size 256 : 8x 10x 1.7 ms
8x 10 loops of size 512 : 8x 10x 1.6 ms
4x 10 loops of size 1 k: 4x 10x 3.2 ms
2x 10 loops of size 2 k: 2x 10x 6.8 ms
1x 10 loops of size 4 k: 1x 10x 13.7 ms
1x 10 loops of size 8 k: 1x 10x 14.8 ms
1x 10 loops of size 16 k: 1x 10x 26.1 ms
1x 10 loops of size 33 k: 1x 10x 157.8 ms
1x 1 loops of size 66 k: 1x 1x 412.4 ms
1x 1 loops of size 131 k: 1x 1x 508.2 ms
KeOps -------------
512x 10 loops of size 256 : 512x 10x 174.8 µs
256x 10 loops of size 512 : 256x 10x 425.6 µs
128x 10 loops of size 1 k: 128x 10x 1.3 ms
4x 10 loops of size 2 k: 4x 10x 5.1 ms
2x 10 loops of size 4 k: 2x 10x 17.4 ms
1x 10 loops of size 8 k: 1x 10x 62.2 ms
1x 10 loops of size 16 k: 1x 10x 220.1 ms
1x 1 loops of size 33 k: 1x 1x 829.4 ms
1x 1 loops of size 66 k: 1x 1x 3.3 s
1x 1 loops of size 131 k: 1x 1x 13.0 s
** Too slow!
KeOps (Nyström landmarks = 256) -------------
2x 10 loops of size 256 : 2x 10x 13.0 ms
2x 10 loops of size 512 : 2x 10x 13.0 ms
1x 10 loops of size 1 k: 1x 10x 27.9 ms
1x 10 loops of size 2 k: 1x 10x 28.5 ms
1x 10 loops of size 4 k: 1x 10x 29.0 ms
1x 10 loops of size 8 k: 1x 10x 30.9 ms
1x 10 loops of size 16 k: 1x 10x 37.5 ms
1x 10 loops of size 33 k: 1x 10x 159.3 ms
1x 1 loops of size 66 k: 1x 1x 419.6 ms
1x 1 loops of size 131 k: 1x 1x 472.1 ms
KeOps (Nyström landmarks = 64) -------------
8x 10 loops of size 256 : 8x 10x 2.5 ms
8x 10 loops of size 512 : 8x 10x 2.8 ms
4x 10 loops of size 1 k: 4x 10x 7.9 ms
2x 10 loops of size 2 k: 2x 10x 12.8 ms
1x 10 loops of size 4 k: 1x 10x 23.8 ms
1x 10 loops of size 8 k: 1x 10x 25.6 ms
1x 10 loops of size 16 k: 1x 10x 29.9 ms
1x 10 loops of size 33 k: 1x 10x 152.0 ms
1x 1 loops of size 66 k: 1x 1x 400.6 ms
1x 1 loops of size 131 k: 1x 1x 441.6 ms
Embedding of dimension 256 = 4 heads of dimension 64.
run_experiment(embed_dim=256, num_heads=4)
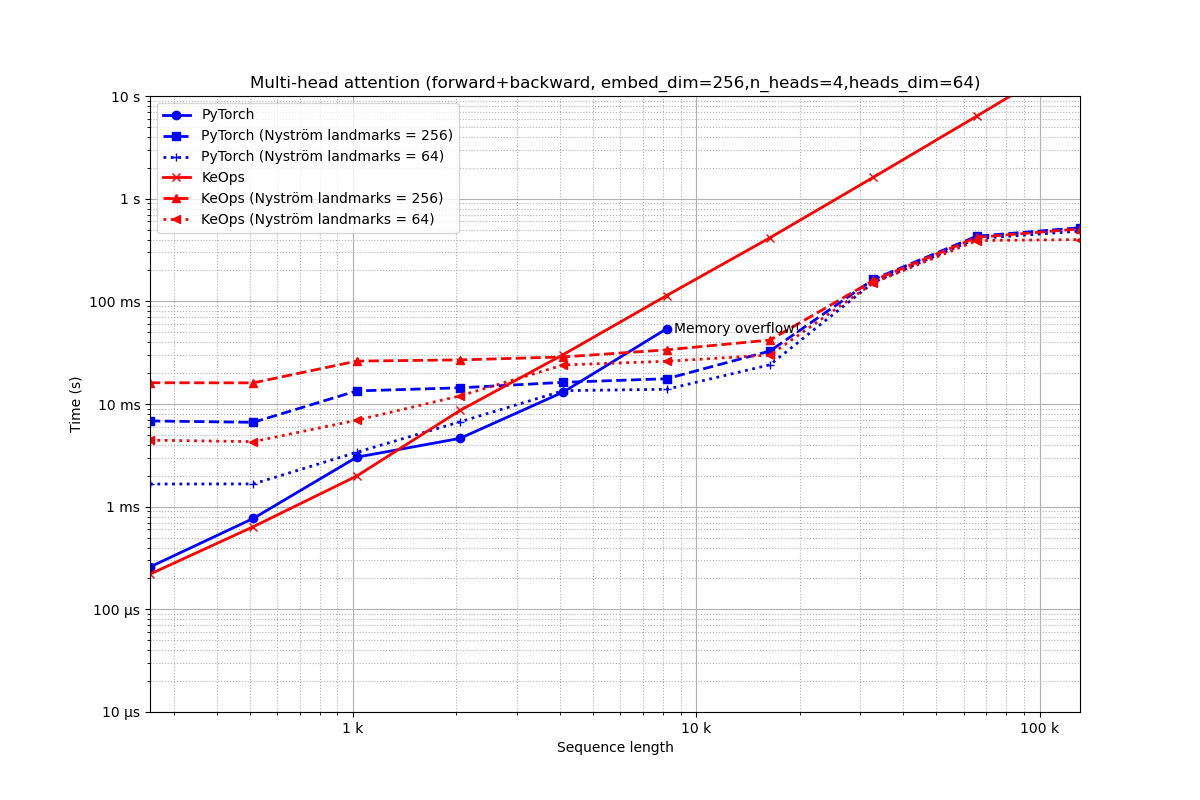
Out:
Benchmarking : Multi-head attention (forward+backward, embed_dim=256,n_heads=4,heads_dim=64) ===============================
PyTorch -------------
16x 10 loops of size 256 : 16x 10x 258.7 µs
4x 10 loops of size 512 : 4x 10x 768.8 µs
1x 10 loops of size 1 k: 1x 10x 3.0 ms
1x 10 loops of size 2 k: 1x 10x 4.6 ms
1x 10 loops of size 4 k: 1x 10x 13.1 ms
1x 10 loops of size 8 k: 1x 10x 54.1 ms
CUDA out of memory. Tried to allocate 1024.00 MiB (GPU 0; 10.76 GiB total capacity; 8.13 GiB already allocated; 742.56 MiB free; 9.00 GiB reserved in total by PyTorch)
** Runtime error!
PyTorch (Nyström landmarks = 256) -------------
2x 10 loops of size 256 : 2x 10x 6.8 ms
2x 10 loops of size 512 : 2x 10x 6.6 ms
1x 10 loops of size 1 k: 1x 10x 13.4 ms
1x 10 loops of size 2 k: 1x 10x 14.4 ms
1x 10 loops of size 4 k: 1x 10x 16.3 ms
1x 10 loops of size 8 k: 1x 10x 17.6 ms
1x 10 loops of size 16 k: 1x 10x 32.8 ms
1x 10 loops of size 33 k: 1x 10x 163.5 ms
1x 1 loops of size 66 k: 1x 1x 430.9 ms
1x 1 loops of size 131 k: 1x 1x 521.4 ms
PyTorch (Nyström landmarks = 64) -------------
8x 10 loops of size 256 : 8x 10x 1.7 ms
8x 10 loops of size 512 : 8x 10x 1.7 ms
4x 10 loops of size 1 k: 4x 10x 3.4 ms
2x 10 loops of size 2 k: 2x 10x 6.7 ms
1x 10 loops of size 4 k: 1x 10x 13.5 ms
1x 10 loops of size 8 k: 1x 10x 13.9 ms
1x 10 loops of size 16 k: 1x 10x 24.1 ms
1x 10 loops of size 33 k: 1x 10x 152.8 ms
1x 1 loops of size 66 k: 1x 1x 408.9 ms
1x 1 loops of size 131 k: 1x 1x 482.9 ms
KeOps -------------
512x 10 loops of size 256 : 512x 10x 220.4 µs
256x 10 loops of size 512 : 256x 10x 638.1 µs
128x 10 loops of size 1 k: 128x 10x 2.0 ms
4x 10 loops of size 2 k: 4x 10x 8.7 ms
2x 10 loops of size 4 k: 2x 10x 30.3 ms
1x 10 loops of size 8 k: 1x 10x 113.8 ms
1x 1 loops of size 16 k: 1x 1x 416.4 ms
1x 1 loops of size 33 k: 1x 1x 1.6 s
1x 1 loops of size 66 k: 1x 1x 6.4 s
1x 1 loops of size 131 k: 1x 1x 25.4 s
** Too slow!
KeOps (Nyström landmarks = 256) -------------
2x 10 loops of size 256 : 2x 10x 16.1 ms
2x 10 loops of size 512 : 2x 10x 16.1 ms
1x 10 loops of size 1 k: 1x 10x 26.2 ms
1x 10 loops of size 2 k: 1x 10x 26.9 ms
1x 10 loops of size 4 k: 1x 10x 28.7 ms
1x 10 loops of size 8 k: 1x 10x 33.7 ms
1x 10 loops of size 16 k: 1x 10x 42.0 ms
1x 10 loops of size 33 k: 1x 10x 159.9 ms
1x 1 loops of size 66 k: 1x 1x 420.0 ms
1x 1 loops of size 131 k: 1x 1x 508.1 ms
KeOps (Nyström landmarks = 64) -------------
8x 10 loops of size 256 : 8x 10x 4.4 ms
8x 10 loops of size 512 : 8x 10x 4.3 ms
4x 10 loops of size 1 k: 4x 10x 6.9 ms
2x 10 loops of size 2 k: 2x 10x 12.0 ms
1x 10 loops of size 4 k: 1x 10x 24.0 ms
1x 10 loops of size 8 k: 1x 10x 26.1 ms
1x 10 loops of size 16 k: 1x 10x 30.0 ms
1x 10 loops of size 33 k: 1x 10x 151.5 ms
1x 1 loops of size 66 k: 1x 1x 390.5 ms
1x 1 loops of size 131 k: 1x 1x 399.6 ms
Embeddings of dimension 1,024¶
Embedding of dimension 1,024 = 256 heads of dimension 4.
run_experiment(embed_dim=1024, num_heads=256)
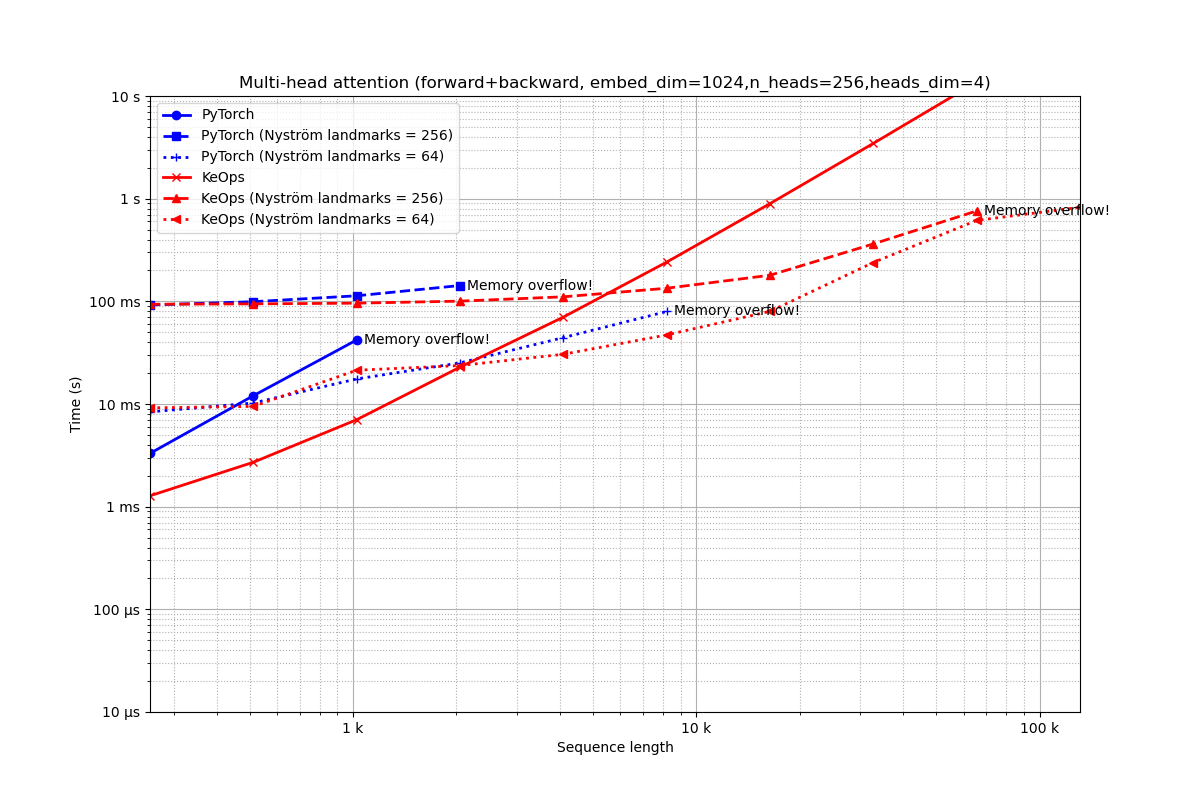
Out:
Benchmarking : Multi-head attention (forward+backward, embed_dim=1024,n_heads=256,heads_dim=4) ===============================
PyTorch -------------
4x 10 loops of size 256 : 4x 10x 3.3 ms
1x 10 loops of size 512 : 1x 10x 12.0 ms
1x 10 loops of size 1 k: 1x 10x 42.0 ms
CUDA out of memory. Tried to allocate 4.00 GiB (GPU 0; 10.76 GiB total capacity; 8.11 GiB already allocated; 742.56 MiB free; 9.00 GiB reserved in total by PyTorch)
** Runtime error!
PyTorch (Nyström landmarks = 256) -------------
1x 10 loops of size 256 : 1x 10x 92.1 ms
1x 10 loops of size 512 : 1x 10x 99.2 ms
1x 10 loops of size 1 k: 1x 10x 113.2 ms
1x 1 loops of size 2 k: 1x 1x 142.6 ms
CUDA out of memory. Tried to allocate 1024.00 MiB (GPU 0; 10.76 GiB total capacity; 8.63 GiB already allocated; 738.56 MiB free; 9.01 GiB reserved in total by PyTorch)
** Runtime error!
PyTorch (Nyström landmarks = 64) -------------
2x 10 loops of size 256 : 2x 10x 8.4 ms
2x 10 loops of size 512 : 2x 10x 10.2 ms
1x 10 loops of size 1 k: 1x 10x 17.5 ms
1x 10 loops of size 2 k: 1x 10x 25.1 ms
1x 10 loops of size 4 k: 1x 10x 44.3 ms
1x 10 loops of size 8 k: 1x 10x 79.6 ms
CUDA out of memory. Tried to allocate 1024.00 MiB (GPU 0; 10.76 GiB total capacity; 7.87 GiB already allocated; 742.56 MiB free; 9.00 GiB reserved in total by PyTorch)
** Runtime error!
KeOps -------------
128x 10 loops of size 256 : 128x 10x 1.3 ms
64x 10 loops of size 512 : 64x 10x 2.7 ms
32x 10 loops of size 1 k: 32x 10x 7.0 ms
1x 10 loops of size 2 k: 1x 10x 22.9 ms
1x 10 loops of size 4 k: 1x 10x 70.2 ms
1x 10 loops of size 8 k: 1x 10x 241.0 ms
1x 1 loops of size 16 k: 1x 1x 895.0 ms
1x 1 loops of size 33 k: 1x 1x 3.5 s
1x 1 loops of size 66 k: 1x 1x 13.7 s
** Too slow!
KeOps (Nyström landmarks = 256) -------------
1x 10 loops of size 256 : 1x 10x 93.7 ms
1x 10 loops of size 512 : 1x 10x 94.5 ms
1x 10 loops of size 1 k: 1x 10x 96.0 ms
1x 10 loops of size 2 k: 1x 10x 100.5 ms
1x 1 loops of size 4 k: 1x 1x 110.7 ms
1x 1 loops of size 8 k: 1x 1x 134.1 ms
1x 1 loops of size 16 k: 1x 1x 179.5 ms
1x 1 loops of size 33 k: 1x 1x 362.5 ms
1x 1 loops of size 66 k: 1x 1x 759.6 ms
CUDA out of memory. Tried to allocate 768.00 MiB (GPU 0; 10.76 GiB total capacity; 8.98 GiB already allocated; 226.56 MiB free; 9.51 GiB reserved in total by PyTorch)
** Runtime error!
KeOps (Nyström landmarks = 64) -------------
2x 10 loops of size 256 : 2x 10x 9.2 ms
2x 10 loops of size 512 : 2x 10x 9.5 ms
1x 10 loops of size 1 k: 1x 10x 21.3 ms
1x 10 loops of size 2 k: 1x 10x 23.7 ms
1x 10 loops of size 4 k: 1x 10x 30.5 ms
1x 10 loops of size 8 k: 1x 10x 47.1 ms
1x 10 loops of size 16 k: 1x 10x 79.8 ms
1x 10 loops of size 33 k: 1x 10x 238.9 ms
1x 1 loops of size 66 k: 1x 1x 613.7 ms
1x 1 loops of size 131 k: 1x 1x 824.5 ms
Embedding of dimension 1,024 = 32 heads of dimension 32.
run_experiment(embed_dim=1024, num_heads=32)
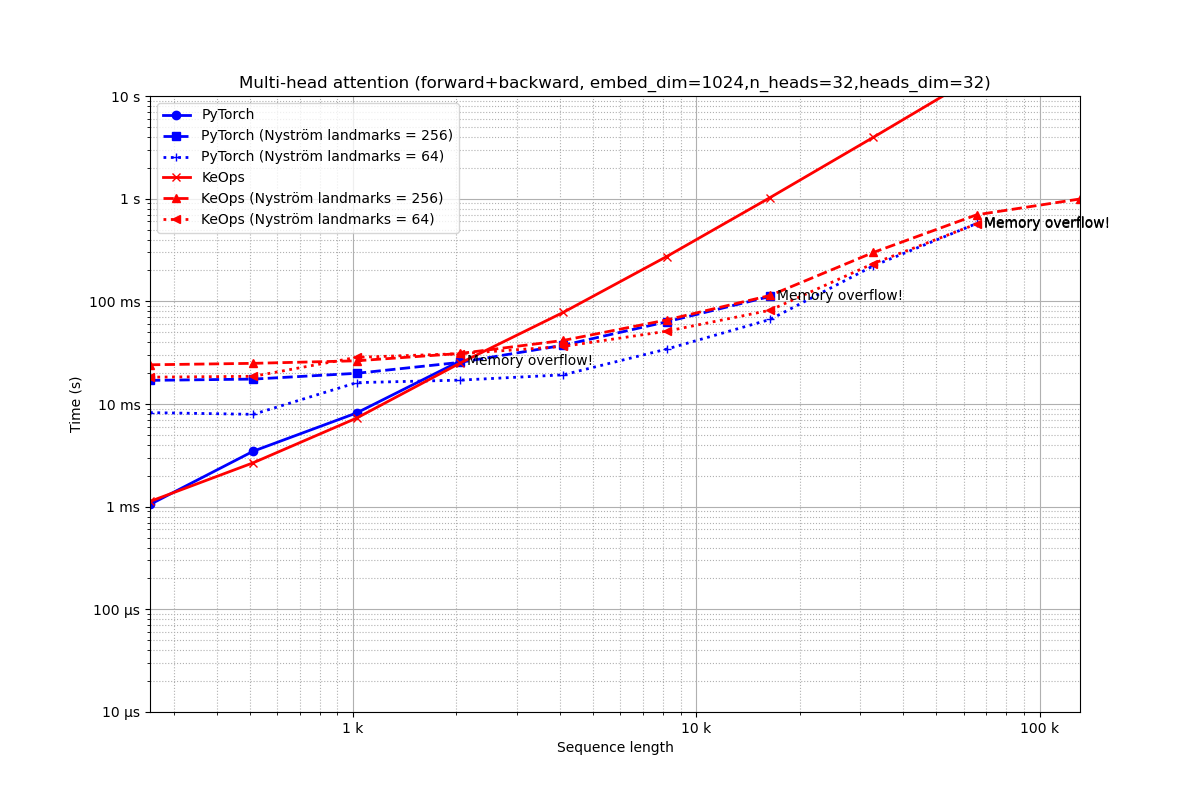
Out:
Benchmarking : Multi-head attention (forward+backward, embed_dim=1024,n_heads=32,heads_dim=32) ===============================
PyTorch -------------
4x 10 loops of size 256 : 4x 10x 1.1 ms
1x 10 loops of size 512 : 1x 10x 3.5 ms
1x 10 loops of size 1 k: 1x 10x 8.2 ms
1x 10 loops of size 2 k: 1x 10x 26.2 ms
CUDA out of memory. Tried to allocate 2.00 GiB (GPU 0; 10.76 GiB total capacity; 8.19 GiB already allocated; 1.23 GiB free; 8.50 GiB reserved in total by PyTorch)
** Runtime error!
PyTorch (Nyström landmarks = 256) -------------
1x 10 loops of size 256 : 1x 10x 17.0 ms
1x 10 loops of size 512 : 1x 10x 17.5 ms
1x 10 loops of size 1 k: 1x 10x 19.9 ms
1x 10 loops of size 2 k: 1x 10x 25.4 ms
1x 10 loops of size 4 k: 1x 10x 37.4 ms
1x 10 loops of size 8 k: 1x 10x 63.2 ms
1x 10 loops of size 16 k: 1x 10x 111.5 ms
CUDA out of memory. Tried to allocate 1024.00 MiB (GPU 0; 10.76 GiB total capacity; 8.20 GiB already allocated; 226.56 MiB free; 9.51 GiB reserved in total by PyTorch)
** Runtime error!
PyTorch (Nyström landmarks = 64) -------------
2x 10 loops of size 256 : 2x 10x 8.2 ms
2x 10 loops of size 512 : 2x 10x 7.9 ms
1x 10 loops of size 1 k: 1x 10x 16.1 ms
1x 10 loops of size 2 k: 1x 10x 17.1 ms
1x 10 loops of size 4 k: 1x 10x 19.2 ms
1x 10 loops of size 8 k: 1x 10x 34.3 ms
1x 10 loops of size 16 k: 1x 10x 66.6 ms
1x 10 loops of size 33 k: 1x 10x 221.5 ms
1x 1 loops of size 66 k: 1x 1x 573.2 ms
CUDA out of memory. Tried to allocate 512.00 MiB (GPU 0; 10.76 GiB total capacity; 9.04 GiB already allocated; 210.56 MiB free; 9.52 GiB reserved in total by PyTorch)
** Runtime error!
KeOps -------------
128x 10 loops of size 256 : 128x 10x 1.1 ms
64x 10 loops of size 512 : 64x 10x 2.7 ms
32x 10 loops of size 1 k: 32x 10x 7.3 ms
1x 10 loops of size 2 k: 1x 10x 25.0 ms
1x 10 loops of size 4 k: 1x 10x 78.1 ms
1x 10 loops of size 8 k: 1x 10x 273.1 ms
1x 1 loops of size 16 k: 1x 1x 1.0 s
1x 1 loops of size 33 k: 1x 1x 4.0 s
1x 1 loops of size 66 k: 1x 1x 15.6 s
** Too slow!
KeOps (Nyström landmarks = 256) -------------
1x 10 loops of size 256 : 1x 10x 24.1 ms
1x 10 loops of size 512 : 1x 10x 24.9 ms
1x 10 loops of size 1 k: 1x 10x 26.3 ms
1x 10 loops of size 2 k: 1x 10x 31.1 ms
1x 10 loops of size 4 k: 1x 10x 41.6 ms
1x 10 loops of size 8 k: 1x 10x 65.9 ms
1x 10 loops of size 16 k: 1x 10x 114.0 ms
1x 1 loops of size 33 k: 1x 1x 299.3 ms
1x 1 loops of size 66 k: 1x 1x 696.4 ms
1x 1 loops of size 131 k: 1x 1x 993.2 ms
KeOps (Nyström landmarks = 64) -------------
2x 10 loops of size 256 : 2x 10x 18.3 ms
2x 10 loops of size 512 : 2x 10x 18.6 ms
1x 10 loops of size 1 k: 1x 10x 28.5 ms
1x 10 loops of size 2 k: 1x 10x 30.9 ms
1x 10 loops of size 4 k: 1x 10x 36.4 ms
1x 10 loops of size 8 k: 1x 10x 51.2 ms
1x 10 loops of size 16 k: 1x 10x 81.9 ms
1x 10 loops of size 33 k: 1x 10x 233.4 ms
1x 1 loops of size 66 k: 1x 1x 568.0 ms
CUDA out of memory. Tried to allocate 512.00 MiB (GPU 0; 10.76 GiB total capacity; 8.10 GiB already allocated; 208.56 MiB free; 9.52 GiB reserved in total by PyTorch)
** Runtime error!
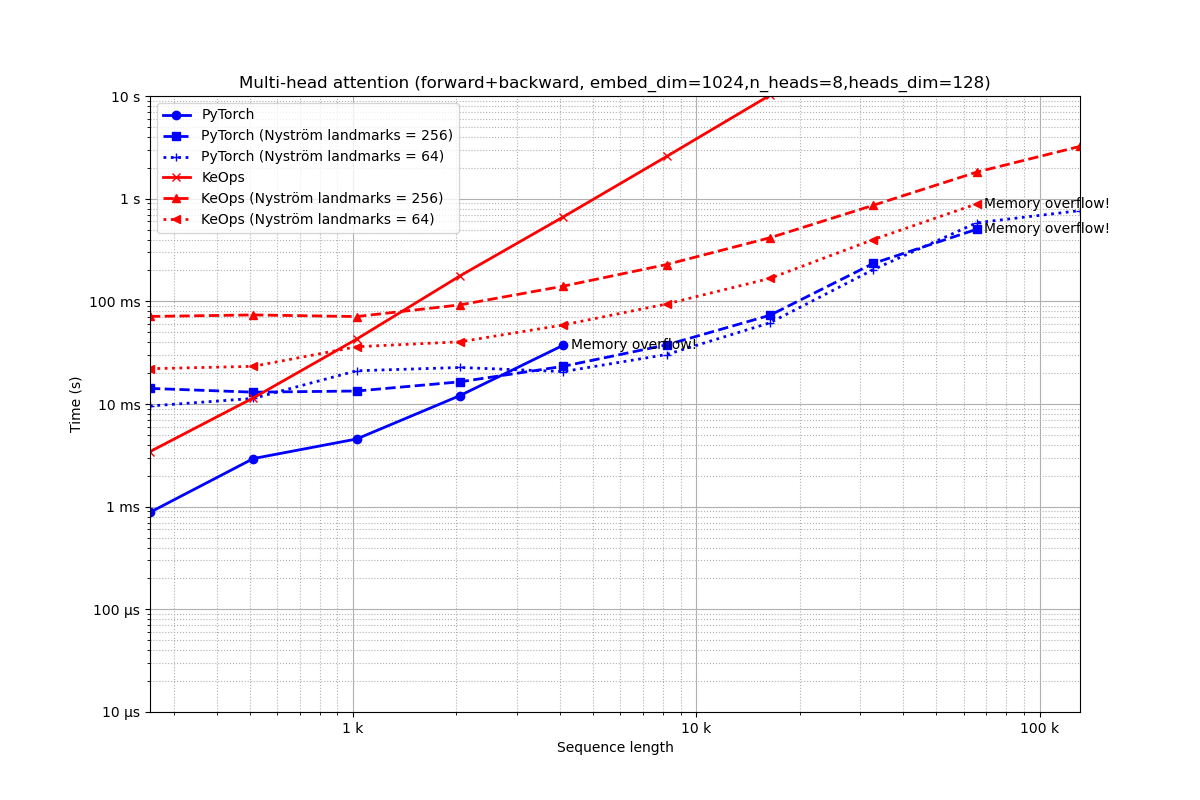
Embedding of dimension 1,024 = 8 heads of dimension 128.
run_experiment(embed_dim=1024, num_heads=8)
plt.show()
Out:
Benchmarking : Multi-head attention (forward+backward, embed_dim=1024,n_heads=8,heads_dim=128) ===============================
PyTorch -------------
4x 10 loops of size 256 : 4x 10x 880.7 µs
1x 10 loops of size 512 : 1x 10x 2.9 ms
1x 10 loops of size 1 k: 1x 10x 4.6 ms
1x 10 loops of size 2 k: 1x 10x 12.1 ms
1x 10 loops of size 4 k: 1x 10x 37.4 ms
CUDA out of memory. Tried to allocate 2.00 GiB (GPU 0; 10.76 GiB total capacity; 8.49 GiB already allocated; 230.56 MiB free; 9.50 GiB reserved in total by PyTorch)
** Runtime error!
PyTorch (Nyström landmarks = 256) -------------
1x 10 loops of size 256 : 1x 10x 14.2 ms
1x 10 loops of size 512 : 1x 10x 13.0 ms
1x 10 loops of size 1 k: 1x 10x 13.4 ms
1x 10 loops of size 2 k: 1x 10x 16.4 ms
1x 10 loops of size 4 k: 1x 10x 23.3 ms
1x 10 loops of size 8 k: 1x 10x 37.7 ms
1x 10 loops of size 16 k: 1x 10x 73.2 ms
1x 10 loops of size 33 k: 1x 10x 234.1 ms
1x 1 loops of size 66 k: 1x 1x 503.2 ms
CUDA out of memory. Tried to allocate 1024.00 MiB (GPU 0; 10.76 GiB total capacity; 8.10 GiB already allocated; 226.56 MiB free; 9.51 GiB reserved in total by PyTorch)
** Runtime error!
PyTorch (Nyström landmarks = 64) -------------
2x 10 loops of size 256 : 2x 10x 9.6 ms
2x 10 loops of size 512 : 2x 10x 11.3 ms
1x 10 loops of size 1 k: 1x 10x 21.1 ms
1x 10 loops of size 2 k: 1x 10x 22.7 ms
1x 10 loops of size 4 k: 1x 10x 20.7 ms
1x 10 loops of size 8 k: 1x 10x 30.3 ms
1x 10 loops of size 16 k: 1x 10x 61.8 ms
1x 10 loops of size 33 k: 1x 10x 203.7 ms
1x 1 loops of size 66 k: 1x 1x 582.2 ms
1x 1 loops of size 131 k: 1x 1x 765.0 ms
KeOps -------------
128x 10 loops of size 256 : 128x 10x 3.4 ms
64x 10 loops of size 512 : 64x 10x 11.5 ms
32x 10 loops of size 1 k: 32x 10x 42.9 ms
1x 10 loops of size 2 k: 1x 10x 176.9 ms
1x 1 loops of size 4 k: 1x 1x 664.9 ms
1x 1 loops of size 8 k: 1x 1x 2.6 s
1x 1 loops of size 16 k: 1x 1x 10.2 s
** Too slow!
KeOps (Nyström landmarks = 256) -------------
1x 10 loops of size 256 : 1x 10x 71.3 ms
1x 10 loops of size 512 : 1x 10x 73.7 ms
1x 10 loops of size 1 k: 1x 10x 71.1 ms
1x 10 loops of size 2 k: 1x 10x 92.3 ms
1x 10 loops of size 4 k: 1x 10x 140.6 ms
1x 1 loops of size 8 k: 1x 1x 228.4 ms
1x 1 loops of size 16 k: 1x 1x 416.3 ms
1x 1 loops of size 33 k: 1x 1x 862.3 ms
1x 1 loops of size 66 k: 1x 1x 1.8 s
1x 1 loops of size 131 k: 1x 1x 3.2 s
KeOps (Nyström landmarks = 64) -------------
2x 10 loops of size 256 : 2x 10x 22.1 ms
2x 10 loops of size 512 : 2x 10x 23.3 ms
1x 10 loops of size 1 k: 1x 10x 36.1 ms
1x 10 loops of size 2 k: 1x 10x 40.4 ms
1x 10 loops of size 4 k: 1x 10x 58.9 ms
1x 10 loops of size 8 k: 1x 10x 94.3 ms
1x 10 loops of size 16 k: 1x 10x 167.4 ms
1x 1 loops of size 33 k: 1x 1x 400.0 ms
1x 1 loops of size 66 k: 1x 1x 889.1 ms
CUDA out of memory. Tried to allocate 512.00 MiB (GPU 0; 10.76 GiB total capacity; 8.06 GiB already allocated; 180.56 MiB free; 9.51 GiB reserved in total by PyTorch)
** Runtime error!
Total running time of the script: ( 10 minutes 48.849 seconds)