What is a GPU?
Before going any further, we should take some time to answer three fundamental questions on Graphics Processing Units, the workhorse of modern image processing and data science:
What is, precisely, a GPU?
How does GPU programming differ from standard (sequential) coding?
How much time and money does it take to benefit from this hardware revolution?
Parallel computing
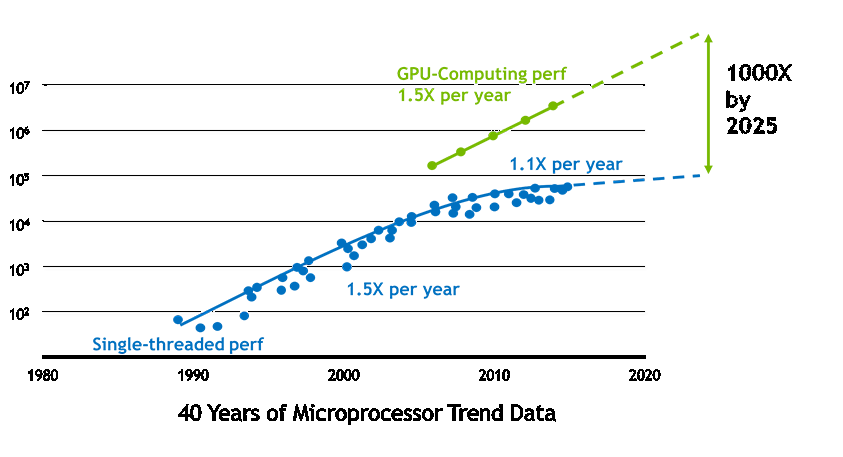
At first glance, GPUs can be described as clusters of cheap but efficient workers that are sold by the thousands on affordable chips. As shown in the Figure below, hardware constructors focus their communication around a simple message: the “GPU revolution” is that of an economy of scale. Since RTX 2080 Ti chips come with 4,352 cores, 11 Gigabytes of memory and can be bought for less than 1,500$, they should be expected to compute large matrix-vector products at a fraction of the cost of a traditional high performance platform.
|

|
Figure. Promotional material taken from the Nvidia website. Most sensibly, hardware constructors focus their marketing strategy on the raw computing power of GPUs and brush under the carpet the key specificity of CUDA programming: finely grained memory management.
Memory management
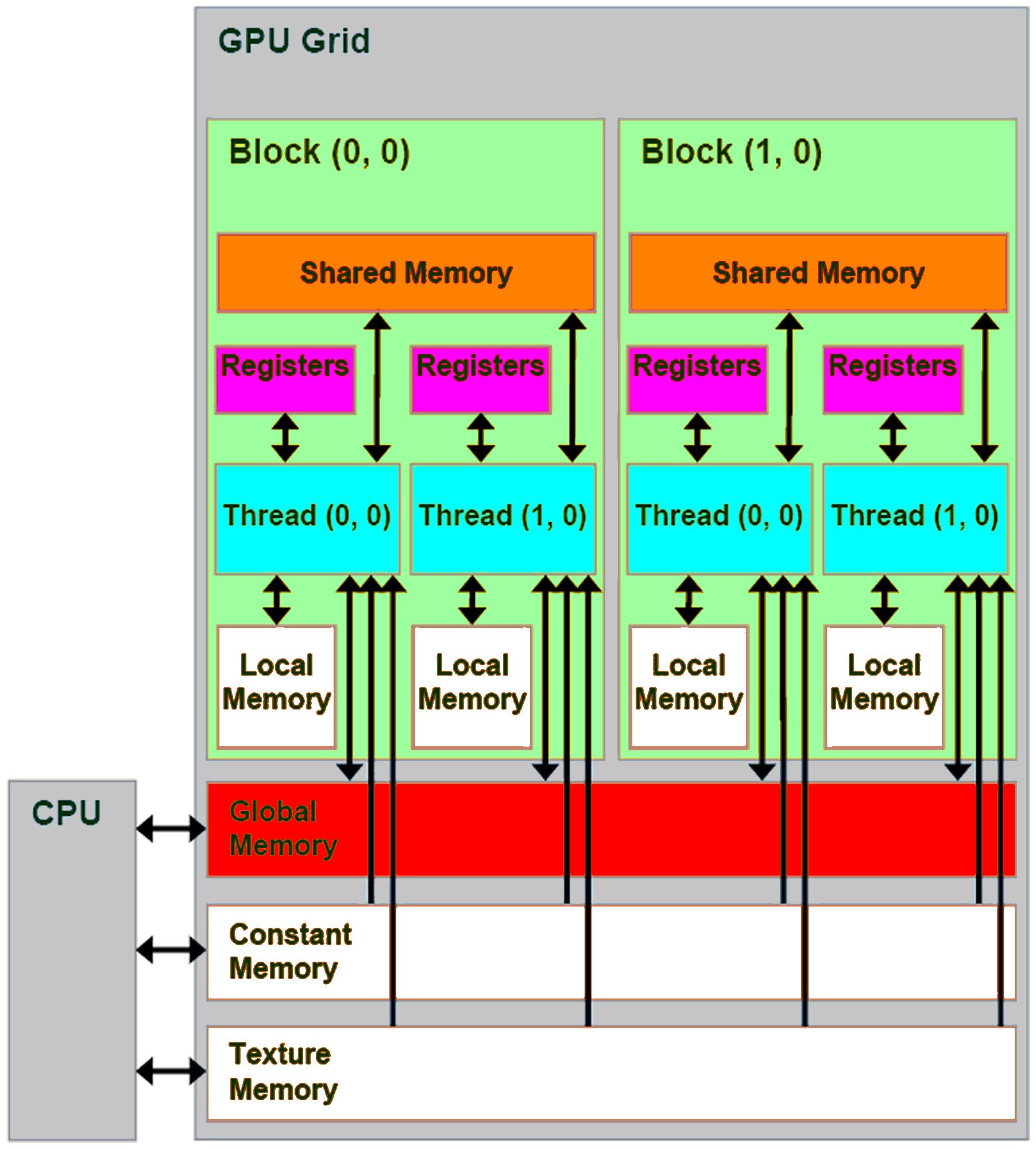
However, as soon as we start diving into the specialized literature, things become murkier. Extracting peak performances from a pool of 4,000+ low-skilled workers is no mean feat: crucially, just like administrators of XIX\({}^\text{th}\) century bureaus, hardware designers have to enforce strict guidelines on the behavior of their cheap “CUDA cores” and hard-code structuring constraints in the circuitry of their devices. Abstracted through the CUDA memory model, the main rules of GPU programming are illustrated in the Figure below and can be summarized as follows:
GPU threads are organized in interchangeable blocks of up to 1,024 workers, which can be identified to the many teams of a large State department.
Far from lying scattered in the device Random Access Memory (RAM), information is finely managed in several layers of hardware. In practice, pushing aside some technicalities, scientific CUDA programs may rely on four different types of memory:
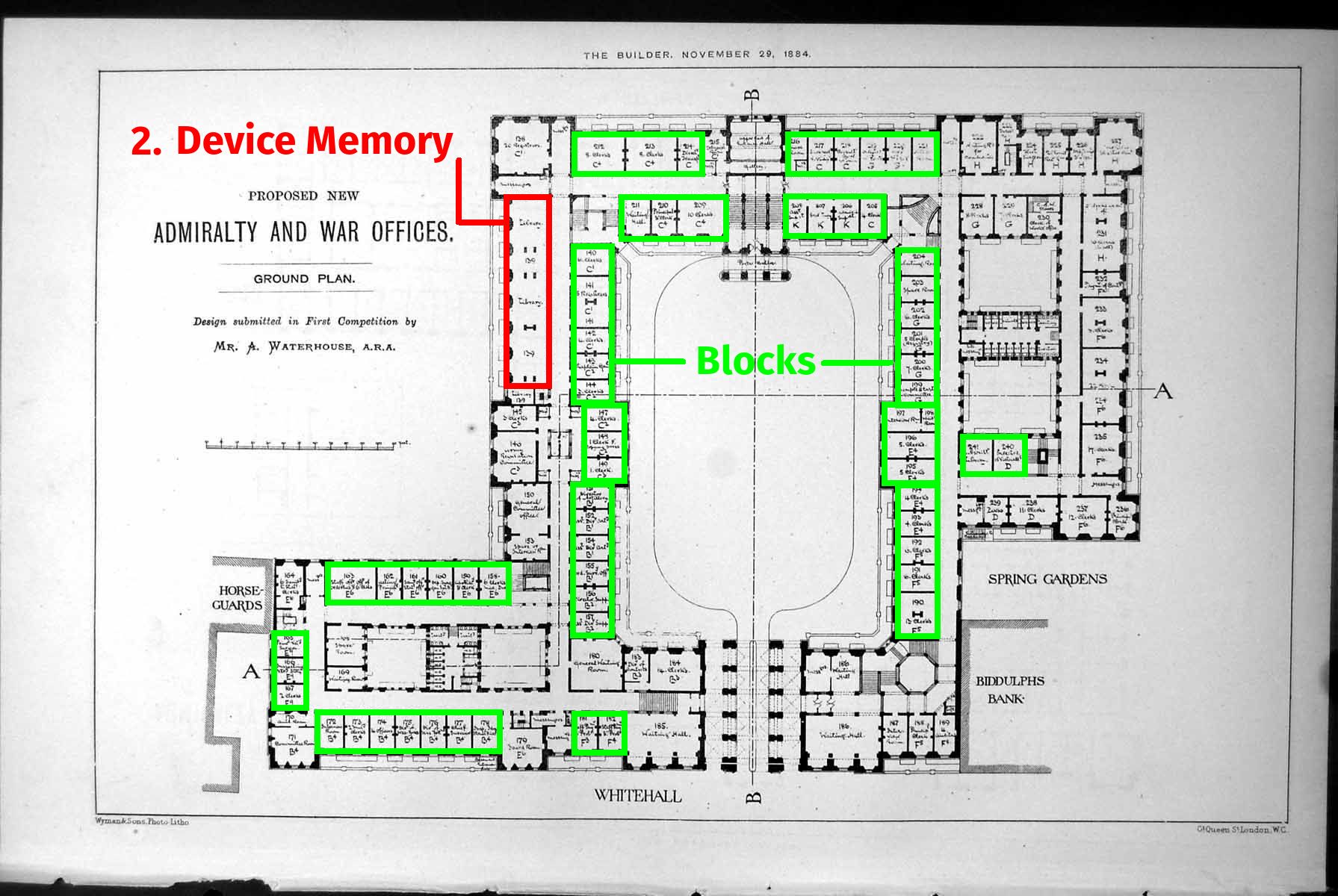
The Host memory, i.e. the usual RAM of the computer that is managed by the main CPU program. It is located far away from the GPU’s computing circuits, which cannot access it directly. In our XIX\({}^\text{th}\) century analogy, it would be represented by the mountains of documentation stored in other State offices, possibly overseas.
The Device memory, which plays the role of a local RAM chip embedded on the GPU. This is the library of our State office, where information is stored before being processed by diligent workers: depending on the model, recent GPUs may be able to store up to 32 Gigabytes of data in this convenient storage location.
The Shared memory which is, well, shared by all threads in a CUDA block. This small buffer may only store up to \(\sim\)96 Kilobytes of data and can be compared to the office shelf of the XIX\({}^\text{th}\) century. Crucially, its latency is much lower than that of the Device memory: optimizing its usage in the KeOps library was the key to a x50 speed-up for all kernel-related operations.
The Register or Thread memory, a very low-latency buffer that is uniquely attributed to each worker – a bit like sheets of scrap paper on one’s desk. A maximum of \(\sim\)256 Kilobytes per block may be attributed this way: values in excess are stored in the (high-latency) Local memory by the compiler.
|
|

|
Figure. Abiding by the same constraints, the architecture of modern GPUs (a) closely resembles that of XIX\({}^\text{th}\) century State departments (b-c) which had to keep track of accounting records for large overseas empires. Organizing their workers in identical teams of a few dozen cores, massively parallel devices rely on a finely grained management of information transfers (3,4) to prevent traffic jams at the gates of the Device memory (2).
To leverage modern GPUs to the best of their abilities, efficient algorithms should thus obey to four guiding principles:
Promote block-wise parallelism. Threads can interact with each other during the execution of a program, but may only do so inside their own CUDA block.
Reduce Host \(\leftrightarrow\) Device memory transfers. Incessant back-and-forth copies between the “CPU” and “GPU” RAMs may quickly become the bottleneck of modern research codes. Fortunately, the TensorFlow and PyTorch APIs now allow users to store and manipulate their data on the device, without ever coming back to the Host memory chip.
Reduce Device \(\leftrightarrow\) Shared/Register memory transfers. Due to the (relatively) high latency of the Device memory, programmers should refrain from storing and handling intermediate buffers outside of the 96 Kb-wide Shared memory of a CUDA block. Unfortunately, the high-level APIs of modern Deep Learning libraries do not allow users to get such a fine-grained control on their computations: this is the main limitation that the KeOps package strives to mitigate, with minimal impact on users’ existing codebases.
Promote block-wise memory accesses. GPUs’ memory circuits are wired in a way that promotes contiguous, page-wise exchanges between the Device and the Shared memories. Initially designed to process triangles and textures at ever faster rates, GPUs are thus somewhat ill-suited to the processing of sparse matrices which rely on rare but random memory accesses.
The CUDA development toolkit
Once these constraints are understood and taken into account, CUDA programming is suprisingly easy. Well aware that the promising “AI-computing” GPU market would never boom without a strong initial investment, Nvidia devoted an impressive amount of effort to the creation of a comfortable development environment: an efficient compiler, good profiling tools, robust libraries… and a comprehensive documentation! To get started with GPU programming, a perfect introduction is the series of tutorials written by Mark Harris on the Nvidia Devblog. In a nutshell, typical CUDA C++ files look like:
// Import your favorite libraries:
#include <iostream>
#include <math.h>
// The __global__ keyword indicates that the following code is to
// be executed on the GPU by blocks of CUDA threads, in parallel.
// Pointers refer to arrays stored on the Device memory:
__global__
void My_CUDA_kernel(int parameter, float *device_data, float *device_output) {
// The indices of the current thread and CUDA block should be
// used to assign each worker to its place in the computation plan:
int i = blockIdx.x * blockDim.x + threadIdx.x;
// The Shared memory is accessed through a raw C++ pointer:
extern __shared__ float shared_mem[];
// Local variables may be declared as usual.
// They'll be stored in the Thread memory whenever possible:
float some_value = 0;
// Transfers of information are handled with a transparent interface:
some_value = device_data[i]; // Thread memory <- Device memory
shared_mem[i] = device_data[i]; // Shared memory <- Device memory
// Whenever required, programmers may create checkpoints for all threads
// in a CUDA block. Needless to say, this may impact performances.
__syncthreads();
// Computations are written in standard C++ and executed in parallel:
for(int k = 0; k < parameter; k++) {
// Blablabla
}
// Finally, results can be written back to the Device memory with:
device_output[i] = some_value; // Device memory <- Thread memory
}
// The main C++ program, executed by the CPU:
int main(void) {
int N = 1024; float *host_data, *host_out, *device_data, *device_out;
// Allocate memory on the device - the API is a bit heavy:
cudaMalloc((void**) &device_data, N*sizeof(float));
cudaMemcpy(device_data, host_data, N*sizeof(float), cudaMemcpyHostToDevice);
// Set the parameters of the CUDA block and run our kernel on the GPU:
int block_size = 128; int grid_size = N / block_size;
int shared_mem_size = 2 * block_size * sizeof(float);
My_CUDA_kernel<<<grid_size, block_size, shared_mem_size>>>(...);
cudaDeviceSynchronize(); // Wait for the GPU to finish its job...
cudaMemcpy(host_out, device_out, N*sizeof(float), cudaMemcpyDeviceToHost);
... // Do whatever you want with the result "output array"...
cudaFree(device_data); // And don't forget to free the allocated memory!
return 0;
}
How much is this going to cost?
Assuming some level of familiarity with C++ programming, designing a CUDA application is thus relatively easy. Thanks to the recent availability of modern – and incredibly convenient – Python/C++ interfaces such as PyBind11, the path that takes scientists from CUDA 101 tutorials to fully-fledged open source libraries is now well trodden. But how expensive are these solutions for academic users?
Nvidia’s de facto monopoly. Due to the costly nature of hardware design, the GPU market is an oligopoly with no more than three constructors in business:
Intel, which produces integrated graphics chips for the mass-consumer market;
Nvidia, the established producer of high-end devices;
AMD, the eternal competitor of Nvidia on the gaming and cryptocurrency markets.
Unfortunately for academics, out of those three players, Nvidia is the only one that invests seriously in the “AI” and “scientific computing” segments, backing up its hardware with state-of-the-art computing libraries. As far as researchers are concerned, GPU computing is thus a captive market, with two ranges of products to pick from:
The GeForce gaming range, with a flagship model sold for \(\sim\)1,500$ and slightly defective or more compact chips marketed at lower prices. As of 2019, the GeForce RTX 2080 Ti provides the best value for money for generic academic purposes.
The data center series, whose slightly more versatile chips are typically sold for \(\sim\)10,000$ per unit. This higher price is justified by a larger Device memory (from 11 Gb to 32 Gb), efficient support of float64 computations, marginal improvements in the circuits’ architectures… and a recently updated license agreement (2018+) for the CUDA drivers, which forbids data centers from deploying devices from the GeForce range.
Cloud solutions. Dedicated machines are must-buys for Deep Learning research teams who intend to use their GPUs full-time for the training of neural architectures. However, for theorists and mathematicians who only ever need to use the latest hardware once a month to produce figures and benchmarks, a smarter option may be to rely on cloud rental services. At affordable rates of \(\sim\)1-3$ per hour – which correspond to amortization periods of one or two months of 24/7 usage – Google, Amazon or Microsoft let customers access their latest machines, free of any maintenance hassle.
Google Colab. Most interestingly, Google provides free GPU sessions to all “GMail” accounts at colab.research.google.com. The constraints that are put on these sessions are clear: 12 hours shelf-life of the virtual machines, privacy concerns when working with real data… But they’re absolutely worth trying out for “casual” students and researchers.
KeOps is portable and free
For the sake of reproducibility and ease of use by our fellow
mathematicians, we made sure that all the packages and experiments
presented on this website run out-of-the-box on free Colab sessions.
Usually, typing !pip install pykeops[full] in a Colab cell is
everything it takes to try our software online: so please play around
with these tools, they’re free as in freedom for everything that’s
explained here, and free as in beer for the rest!